文字を認識するOCRが生まれるまで(アップステージ社内のOCR画像データ収集チャレンジ)
2023/02/21 | 3分
-
ヘイリー (コンテンツコミュニケーション)
-
OCR, Document AIについて知りたい方
アップステージOCRの技術力が気になる方
-
撮影された画像の中の文字を認識し、様々な産業のデジタルイノベーションに活用されているOCR技術をご存知ですか? 人の後処理作業なしで文書の自動化を可能にしたアップステージDocument AIが誕生するまで、スターたちがOne teamでモデル学習用のデータを収集し、性能の礎を築いた社内OCR画像データ収集チャレンジをご紹介します。
-
✔️ 社内画像データ収集イベントの背景と目的
✔️ 収集対象画像
✔️ 精度の高いモデル実装のために重要なデータ
✔️ イベントで集めたデータ
✔️ 社内画像データ収集イベントの効果
✔️ アップステージデータチームの計画と抱負
最近、ハンファ生命と光学文字認識ソリューション「Document AI」の供給契約を締結したアップステージ!診療費領収書など保険請求書類5種の文書を効率的に処理するアップステージのノーコード・ローコードAIソリューション「Document AI」が業界初導入され、金融圏のAI革新をリードすることになりました。 このようなDocument AIが開発されるまで、アップステージのスターたちはOne Teamで最高性能のソリューションを作るために努力しましたが、その過程でOCRモデル学習のための社内画像データ収集イベントを開き、スターたちが一心同体で画像データを集めるチャレンジを行いました。
様々な努力のおかげで、アップステージのDocumentAIは基本モデルの性能だけでも95%以上の精度を 示し、人の後処理作業なしで文書の自動化を可能にしました。 このようなDocument AI誕生の礎となった昨年の社内画像データ収集チャレンジの話をアップステージのデータマネージャー、ジュヒョンさんとのインタビューで振り返ってみました。
最高性能のAIOCR、Upstage Document AIを見る→] [最高性能のAIOCR、Upstage Document AIを見る→].
社内画像データ収集イベントを
開催した背景と目的は何ですか?
アップステージでは、韓国語と英語に特化したOCR(Optical Character Recognition(光学式文字認識)モデル、'ドキュメントAI'を開発しました。Document AI'を作ってサービスしています。OCRは撮影された画像の中の文字(Text)領域を検出、認識し、様々な産業のデジタル革新に活用されている技術です。
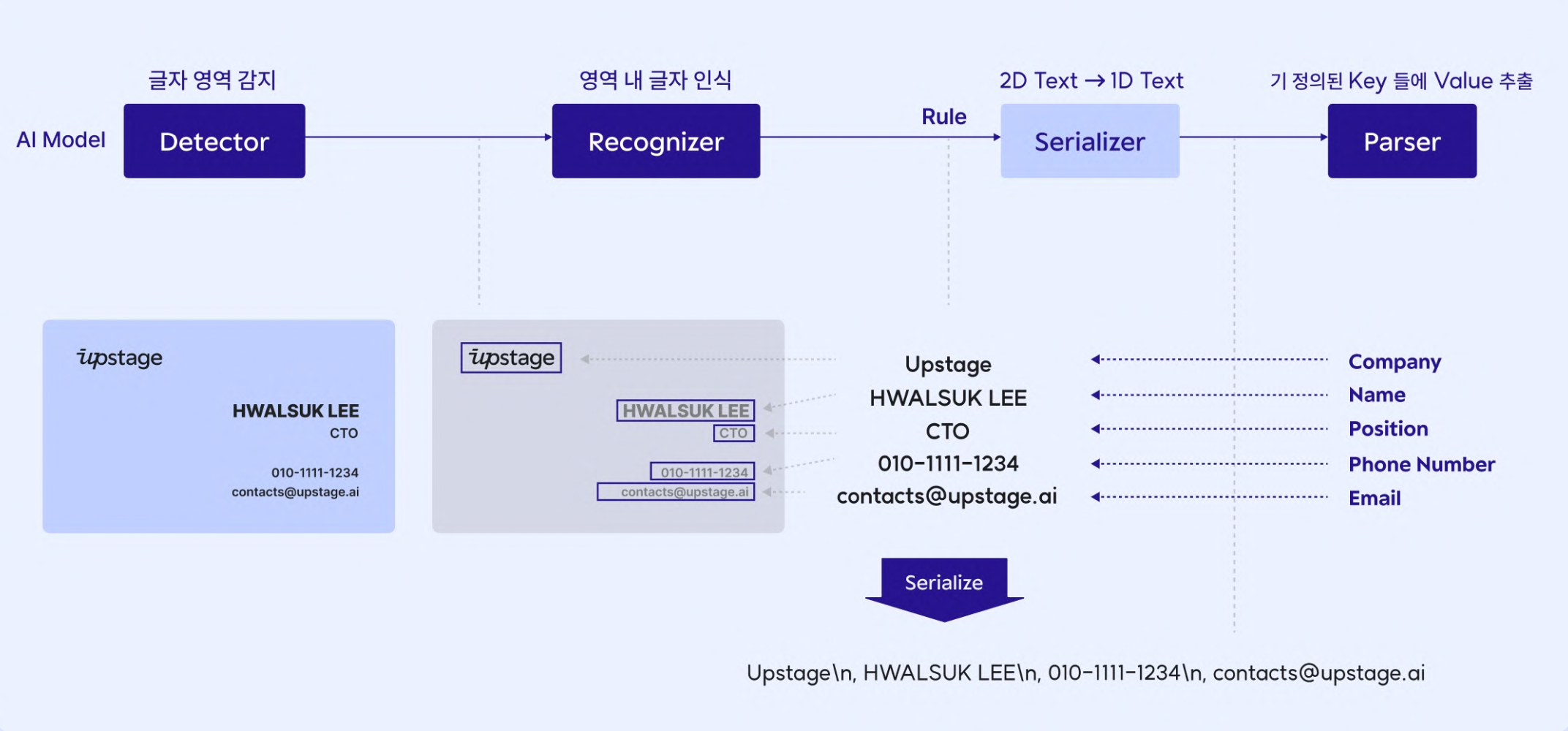
OCR(Optical Character Recognition)技術の説明
このモデルを作るためには、大量のデータを通じてモデルを学習する過程が必要です。 既存に私たちが活用していたパブリックデータ以外にも多くの部分が追加で必要なので、ここに活用できるデータを集めようと、社内で画像データ収集イベントを企画しました。 画像の特性に応じてポイントを付与し、Top3とランダム2名には所定の賞品を支給し、より多くの方が楽しく参加できるようにしました。
特に、昨年3月に行った2回目の社内画像データ収集イベントは、日常でよく見られるScene text(横書き、看板、本の内容など)以外にも、縦書き、手書きなどの特殊なケースをたくさん集めて、この部分での性能をもっと発展させようという趣旨で始まりました。
どのような画像が収集対象でしたか?
ハングルまたはローマ字(アルファベットベースの文字)を含む被写体を含む写真を撮影して提出できるようにしました。 特に強健なモデルの学習のために、文字の大きさや形(フォント)、角度などが多様に現れたものを良いデータとみなし、提出する画像の特性に応じて加点項目を分けました。 アップステージの既存モデルが弱かった特性を考慮して 、縦書き、手書き、エンボス音刻、電光掲示板やデジタル時計のように点/線の組み合わせで構成された文字、そして下線や蛍光ペンなどで文字の境界に侵入がある 場合、加点ポイントを付与しました。



左から縦書き、手書き、エンボス加工の例です。
また、私たちのOCRモデルのデモサイトを開いて、現在のモデルが苦手とする画像が何か、スターの方々が直接デモサイトに画像をアップロードすると、モデルの予測結果を確認できるように 作って、楽しく参加できるように構成しました。

社内の画像データ収集イベント提出の参考になったアップステージOCRデモサイト
AIモデル学習のためのデータの重要性はよく聞きましたが、
正確なモデルを実装するためにはどのくらいのデータが必要ですか?
目標とする精度によって必要なデータ量は変わってきます。 一般的なScene textデータの場合、人間が見たときにかなり使えるレベルになるためには、モデル学習に約5万枚程度のデータが必要です。 もちろん、学習データは多ければ多いほど良いので、弊社も社内イベントでできるだけ多くの画像データを集めるようにしました。
イベントでどれだけのデータが集まりましたか?
多くのスターがOne teamで参加してくれたおかげで、合計7,570枚の画像データを追加で集めることができました。高得点者Top 2の栄誉はバンさん(4.326点)、ユジョンさん(3.373点)に与えられました。 特に1位のバンさんは、様々な戦略でイベントに熱心に参加してくれたのが印象に残っています。加算点が付与される項目を集中的に攻略して縦書きの画像を大量に確保できる書店に行かれたそうです。 本棚に並べられている本のタイトル写真で縦書きの項目で高い加算点を獲得されました。
そして、個人別に提出した画像のスコアを確認できるリーダーボードを一緒に運営したのですが、これが30分に1回更新されるため、締め切りまでの上位は目くじら立てが激しかったそうです。 締め切り直前に画像を提出し、最終結果が目立たないように高度な戦略を立てたという面白い裏話も聞くことができました。

社内画像データ収集イベントで1位を獲得したスターの投稿事例(縦書き)。
社内画像データ収集イベントを通じてどのような効果がありましたか?
モデルの性能はテストセットや測定方法によって異なるので、通常、あるドメインで性能が良くなると他のドメインで性能が悪くなるなど、比較が難しいのですが、今回の社内イベントで集めたデータを追加で使用した場合は、明らかにすべてのドメインで性能が向上し、驚きました。
特に、手書きや珍しいスタイルの文字など、モデルの性能が低下する場合の画像を集中的に収集して、モデルの問題を定量的に確認できたことも、イベントを通じて得られた主な成果の一つです。 これまでは、問題把握のためのテストセットを除いて学習データが十分ではなかったので、十分な学習データが集まるまで、モデルの性能に関して経験的な側面からアプローチするしかありませんでした。 しかし、社内イベントを通じて学習用の画像データをたくさん集めることができ、おかげで特殊なケースに対するテストセット構成やモデルの問題を定量的に測定することができました。
今回のイベントでは、汎用OCRモデルの性能向上のためにScene textが収集対象でしたが、ある程度定型化されている文書のテキストに比べて、文字の形や大きさ、特性などがバラバラなので、ここで訓練されたモデルを持つことで、その後の様々なタスクに発展するための基礎ができたと思います。
最近、ハンファ生命に供給することになったOCRモデルは文書に特化しており、汎用OCRモデルとは異なる領域ですが、アップステージDocument AIの開発初期に、一つのことだけに集中して作られたモデルを構築するのではなく、基本を備えたモデルを作ろうという私たちだけの仮説、目標を立てたことが良い足がかりになったと思います。
アップステージOCRの頼もしい柱となっているデータチーム!
今後の計画や抱負が知りたいです。
今年のデータチームの目標は、エンジン開発に必要なデータをタイムリーに供給することです。
Document AIエンジンチームと協業する部分が多いので、チャレンジを一緒に解決できるデータを作るために努力しています。 その例として、私たちが最近注力している文書特化型モデルに必要な文書内の手書きやチェックボックス、スタンプなどの認識性能を高めることに注力しています。 このように様々なデータをタイムリーに供給するために、データ構築パイプラインの自動化と効率化に必要な部分を考えています。
個人的には、生データの形、モデル学習に最適化されたアノテーションの方法など、タスクごとに適切なデータを設計することに重点を置いています。 チームメンバーと一緒に今年の目標を達成して、アップステージのDocument AIがさらに輝けるように頑張りたいです
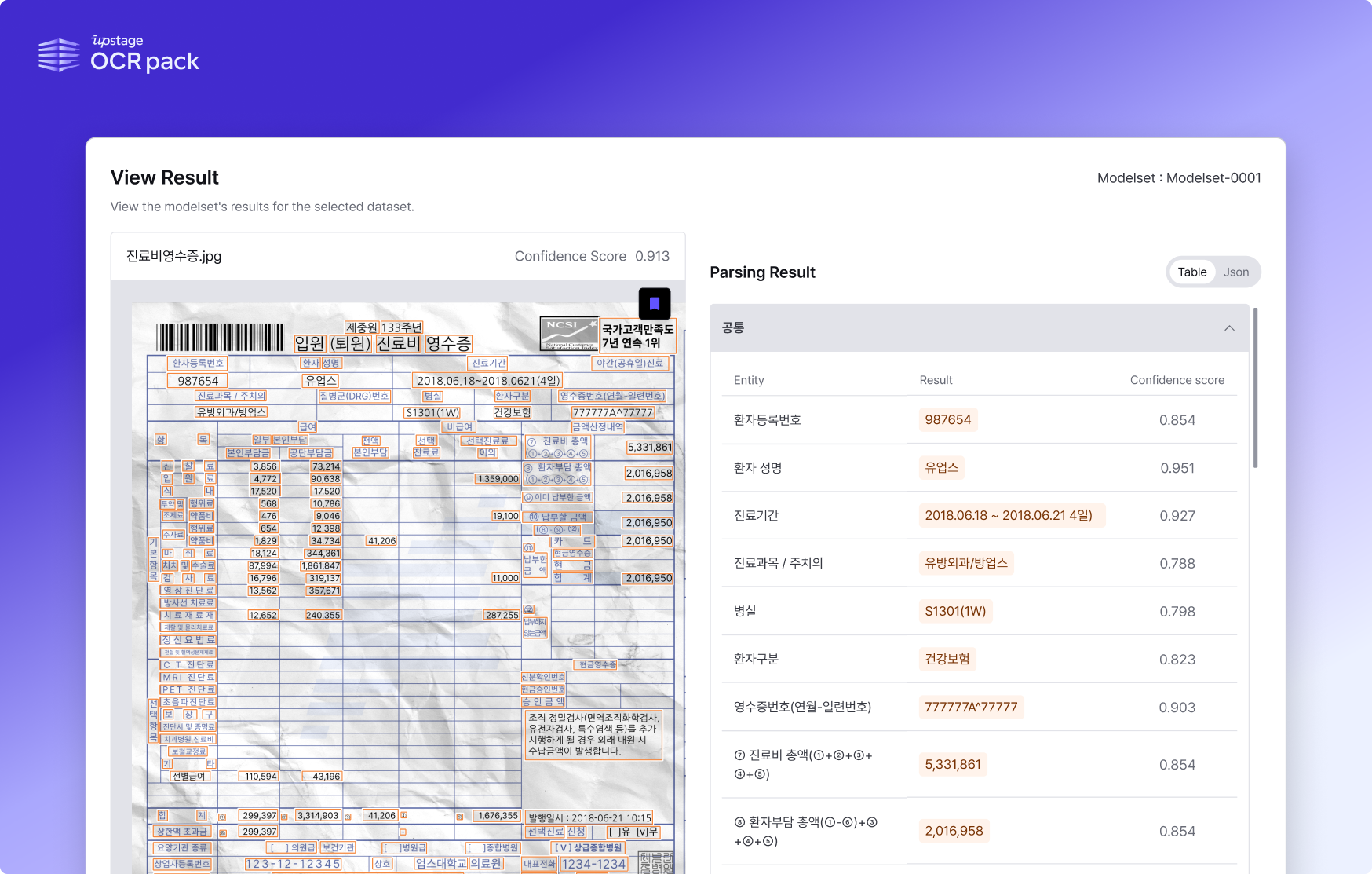
アップステージの光学式文字認識ソリューション「Document AI」を活用し、しわや破損のある診療費領収書を処理するデモシーン
Event
データの資産化で新しい価値を創造しましょう
アップステージコンソールでDocument AI APIを自由にテストして、好きなサービスを作ってみてください!
-
-
2020年10月に設立したアップステージは、画像から目的の情報を抽出して利用できるOCR技術をはじめ、顧客情報と製品・サービスの特徴を考慮した推薦技術、意味ベースの検索を可能にする自然言語処理検索技術など、最新のAI技術を様々な業種にカスタマイズして簡単に適用できるノーコード・ロックコードソリューション「Upstage AI Pack」を発売し、顧客企業のAI革新を支援している。Upstage AI Packを利用すれば、データ加工、AIモデリング、指標管理を簡単に活用できるだけでなく、継続的なアップデートをサポートし、常時最新化されたAI技術を便利に使用することができる。また、AIビジネス経験を溶け込ませた実習中心の教育と堅実なAI基礎教育を通じて、AIビジネスに即座に投入できる差別化された専門人材を育成する教育コンテンツ事業にも積極的に取り組んでいる。
アップステージはGoogle、Apple、Amazon、NVIDIA、Meta、Naverなどのグローバルビッグテック出身のメンバーを中心に、NeurPSをはじめ、ICLR、CVPR、ECCV、WWW、CHI、WSDMなど世界的権威のあるAI学会に多数の優秀論文を発表し、オンラインAI競進大会Kaggleで国内企業の中で唯一2桁の金メダルを獲得するなど、独自のAI技術リーダーシップを確立している。アップステージのキム・ソンフン代表は、香港科学技術大学教授として在職しながら、ソフトウェア工学と機械学習を融合したバグ予測、ソースコード自動生成などの研究で最高の論文賞であるACM Sigsoft Distinguished Paper Awardを4回受賞し、International Conference on Software Maintenanceで10年間最も影響力のある論文賞を受賞した世界的なAIの教祖と言われ、合計700万ビュー以上を記録した「みんなのためのディープラーニング」講師としても広く知られている。また、アップステージの共同創業者には、Naver Visual AI / OCRをリードし、世界的な成果を出したイ・ヒョルソクCTOと世界最高の翻訳機パパゴのモデルチームをリードしたパク・ウンジョンCSOが参加している。