[AIと著作権法】私が作ったAIモデルは合法なのか、違法なのか?
2023/02/14 | 3分
-
ヘイリー (コンテンツコミュニケーション)
この記事は、アップステージAI Education & Contentチームの教育資料をもとに作成されました。
-
AIを扱っている方
サービス向けAIモデル作成に興味のある方
AI関連の著作権法が気になる方
-
良いAIモデルを作るために不可欠な大量学習、これに使われる様々なデータは著作権法を遵守して活用されているのでしょうか?課題とデータが与えられた教育環境の外で、サービス向けのAIモデルを合法的に作るために知っておくべき著作権法について紹介します。
-
✔️ 著作権法、なぜ知っておくべきか?
✔️ 著作権法とは?
✔️ 合法的なデータ使用方法
✔️ AIをやっているとよく遭遇する著作権事例があります。
✔️ 著作権法のグレーゾーン、AI
最近、ChatGPT、ミッドジャーニー(Midjourney)などの生成AIが連日話題を集め、AIの著作権に対する関心が高まっています。 では、私たちがAIモデルを作成する際に使用する様々なデータは、著作権法を遵守して活用されているのでしょうか?
今回のコンテンツでは、課題とデータが与えられた教育環境の外で、サービス向けAIモデルを合法的に作るために知っておくべき著作権法について紹介します。 特に、NLP(自然言語処理)技術を基盤としたAIモデルのデータ作成過程でよく遭遇する事例と疑問点を一緒に考えます。
著作権法、なぜ知っておくべきか?
良いAIモデルは良いデータから生まれる。
学校のような教育環境でAIモデルを開発する場合、通常、先生やカリキュラム運営者の方が著作権に問題のないデータやタスクを用意してくれるので、これについてはあまり心配する必要はありません。しかし、実際の現場に出ると、自分が解きたい問題を解くモデルを作るためには、適切なデータを自分で探して作らなければなりません。 これを単純に考えて、ウェブ上にあるデータを適当にクロールしてモデル学習に活用すると、知らず知らずのうちに著作権法に違反する可能性があります。 したがって、私たちはAIモデル開発に必要なデータを製作する前に、著作権法について知る必要があります。
それだけでなく、学界でも著作権とライセンスについて注目されています。論文内容の知的財産権侵害の有無やデータ収集方法などについて別途質問をしているため、学界にいる方も著作権を正しく理解して活用することが必要です。

学界も注目している著作権(出典:自然言語処理国際共同会議、ACL-IJCNLP 2021)
AIとクリエイターの両方を考慮した良い方向の法改正のために関心を持つ必要がある。
著作権に関心を持つべき第二の理由は、著作権法がまだAIモデルの開発を考慮していない部分が多いからです。 逆説的かもしれませんが、AIのポジティブな発展のために誰もが関心を持つ必要があるのです。良いAIを作るためには大量学習が必須ですが、AI学習用データ活用時の著作権侵害に関する明確な基準がまだありません。
著作権法第1条(目的)を見ると、「この法律は、著作者の権利及びこれに隣接する権利を保護し、著作物の公正な利用を図ることにより、文化及び関連産業の向上発展に寄与することを目的とする」と記載されています。これをじっくり読んでみるとわかるように、現在の著作権法は まだ「AI産業」を考慮していません。なぜなら、法律が制定された当時は、AIが今ほど注目されておらず、性能も現在のレベルに達していなかったからです。
2020年からは、このような現在の流れを反映してAI分野の著作権免責条項が新設された著作権法改正案が推進されていますが、AIと創作者の両方を考慮した良い方向の法改正のためには、継続的な関心が必要です。
著作権法とは?
では、著作権とは何でしょうか?定義を見ると次のようになります。
著作権:人の考えや感情を表現した結果物(著作物)に対して創作者に与える権利で、「創作性」があれば、別途の登録手続きなしに自然に発生します。
(例:アーティストAが描いた絵の著作権は、著作者であるAに当然帰属する)
では、著作物について法律ではどのように記述されているのでしょうか?
著作物:人の考えや感情を表現した成果物。
小説・詩・論文・講演・演説・脚本・その他の語学著作物
音楽著作物
演劇・舞踊・舞踊・その他の演劇著作物
絵画・書道・彫刻・版画・工芸・応用美術著作物その他の美術著作物
建築物・建築のための模型及び設計図書その他の建築著作物
写真著作物(これと同様の方法で製作されたものを含む)
映像著作物
地図・図表・設計図・約図・模型その他の図形著作物
コンピュータプログラム著作物
このように様々な種類の著作物がありますが、AIを扱う方は、テキストや画像著作物に関する話はよく耳にしたことがあると思います。言語、音楽、映像、写真著作物など、AIモデルの開発に必要な部門も著作物として保護されています。
しかし、著作権法によって保護されない著作物もあります。
著作権法で保護されていない著作物
憲法・法律・条約・命令・条例及び規則
国または地方自治体の告示・公告・訓令その他これに類するもの
裁判所の判決・決定・命令及び審判や行政審判手続その他これに類する手続による議決・決定等
国又は地方公共団体が作成したもので、第1号から第3号に規定するものの編集物又は翻訳物。
事実の伝達に過ぎない時事報道
主に国または地方自治体が作成した創作物がこれに該当し、創作性があると見なされにくい時事報道が含まれます。
それでは、これまでの内容をもとに、著作権について実生活で起こりうる疑問を振り返ってみましょう。
[Case 1]
Q.判例検索サービスを提供するモデルを作って配布したいのですが、大丈夫でしょうか?A. はい、可能です。判例は著作権法によって保護されない著作物として規定されているため、これを基に営利目的のサービスを作ったり、研究目的で活用しても著作権法に違反しません。
[Case 2]
Q.アップステージブログのコンテンツがとても印象的で、コメントを残しました。 このコメントの著作権は私にありますか?A. コメントの内容によって異なります。「とても良かったです!」のように誰でも普遍的に書ける文章であれば著作権の保護は受けられませんが、「創作性」が認められるレベルの文章には著作権が付与されます。
例えば、ヘミングウェイが書いた6語の非常に短い小説のような場合には、創作性が認められるので、ヘミングウェイが著作権を持つことになるのです。
では、創作性が認められる著作物には当然著作権が発生しますが、AIモデル学習のためのデータはどのようにすれば正しく使えるのか、もっと詳しく説明します。
合法的なデータ使用方法
1.著者との協議
著作権者と直接交渉して利用方式について協議する方法です。通常、ホームページに著作物について協議できる連絡先やメールアドレスが記載されており、これを介して交渉して協議を進めればよいです。利用方式協議には様々な方法がありますが、韓国著作権委員会が明示した契約書の内容によると、大きく分けて著作物利用の許可を受けることや著作財産権を譲り受けるなどの方法があります。
出典. 韓国著作権委員会著作権標準契約書
上記の案の意味を解釈すると次のようになります。
(1) 著作財産権の独占的/非独占的利用許諾
排他的利用許諾:著作者は、契約を締結した利用者にデータ利用に対する「排他的」な権利を行使することを許可すること。
非独占的利用許諾:著作者は契約を締結した利用者以外にもデータ利用契約を結ぶことができる。
(2) 著作財産権の全部/一部に対する譲渡
自然発生した著作財産権の全部又は一部を譲渡することができる権利です。著作財産権の全部又は一部を譲渡することができ、一定の期間を定めて譲渡することも可能です。
では、いちいち契約を結んで使用する以外に方法はないのでしょうか?著作者と利用者双方にとって効率的な方法がありますが、「ライセンス」がその役割を果たします。
2.ライセンス
合法的にデータを使用できる第二の方法は、著作者が明示した利用許諾規約、つまり「ライセンス」を活用することです。ライセンスは、著作者に利用許可を要請しなくても、著作者が提案した特定の条件を満たせば活用できるようにした規約です。
ライセンスを発行する団体は様々ですが、その中で最も有名なのはCreative Commonsという非営利団体が提供する「CCL」があり、これをベースに国内には文化体育観光省が提供する「公共ヌリ」があります。
CCLが表す意味
BY: アトリビューション
ND: NoDerivatives
NC: 非商用
SA: ShareAlike
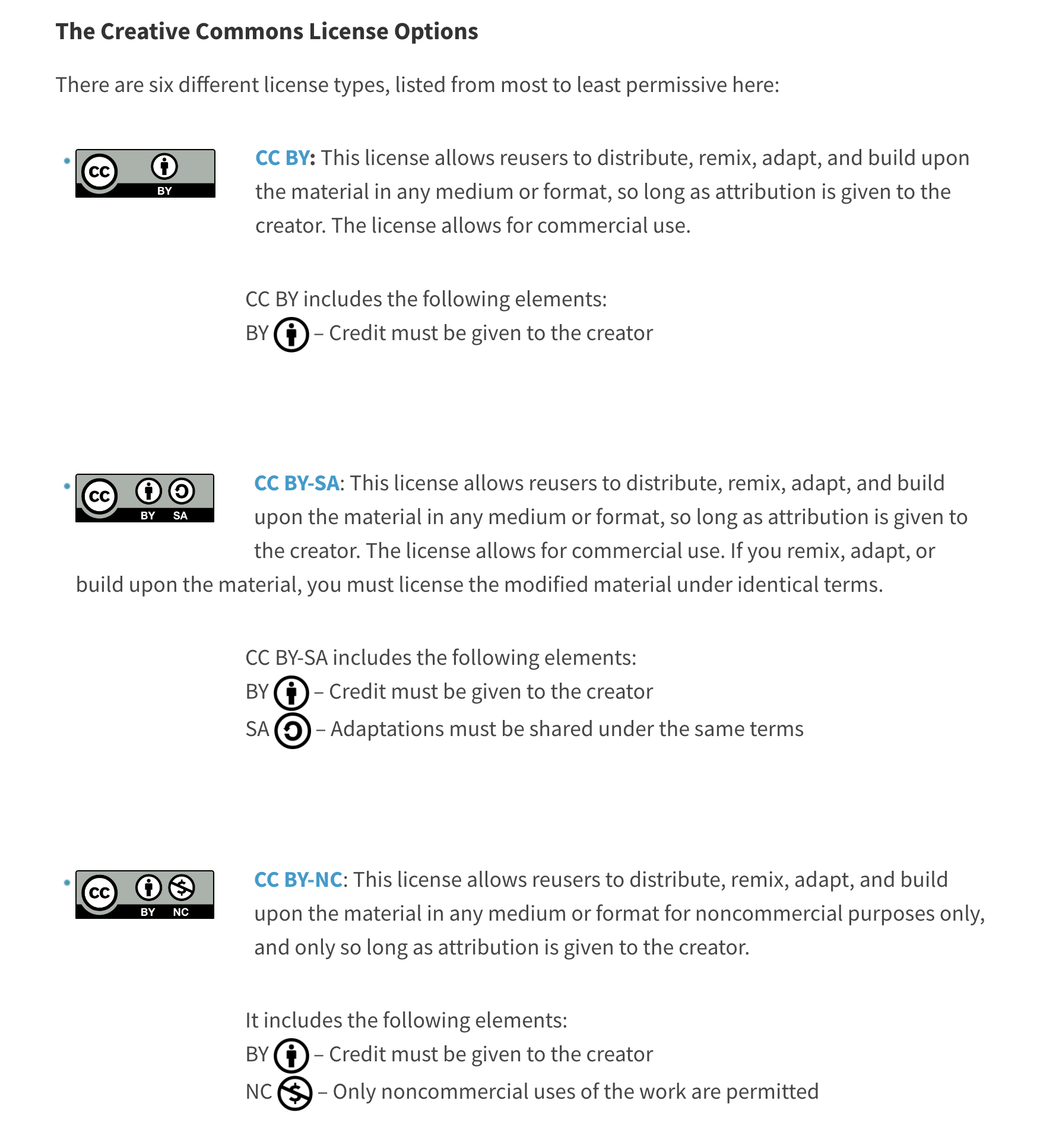

国際的に多く活用されているCCL (出典:Creative Commonsホームページ)
このうち、CC-BY-NC-SAの代表的な事例としては「wiki」があります。AIモデル開発にWikiのデータを活用したい場合は、次のような条件で活用することができます。
[Case 3]
Q.WikiのデータをクロールしてMRC(Machine Reading Comprehension、AIアルゴリズムが自ら問題を分析して質問に最適化された答えを見つける技術)データセットを作成した後、個人GitHubを通じて配布することは可能ですか?A. 学校所属であれば、非営利目的とみなされますので可能です。ただし、配布する場合でも、必ず原データのライセンスであるCC-BY-NC-SAを添付し、原データの出所を明記する必要があります。
もう一つの例としてCC-BY-NDを見てみましょう。 これは著作者表示を意味するBYと変更禁止のNDが合わさったライセンスです。 これの代表的な例としては、韓国語のNLPをする方ならよく知っている'KorQuad'があります。KorQuAD'というデータセットがこのようなライセンスを付けて配布しています。
[Case 4]
Q.KorQuADの質問だけ変えて、新しくMRCデータセットを作成した後、個人ギグハブに配布してもいいですか?A. 変更禁止条件がかかっているため、KorQuADの指紋、質問、正解ペアを変更して公開することはできません。
その他、AIモデルを開発しているとよく遭遇する著作権関連の事例にはどのようなものがありますか?
AIをやっているとよく遭遇する著作権の事例
ニュースデータの利用
まず、ニュースデータもAIモデル開発時によく目にする事例です。しかし、ニュース記事の著作権は報道機関にあるという事実を認識する必要があります。

国内報道機関の著作権表記事例
現在、韓国メディア振興財団では、ほとんどのメディアの著作権を委託して管理しています。 したがって、ニュース記事を合法的に使用するためには、その記事を提供するメディアが韓国メディア振興財団に著作権委託を任せた場合、財団側に問い合わせて、そうでない場合は、直接メディアにコンテンツ使用範囲と契約条件について問い合わせる必要があります。通常、メジャーメディアは、著作権を韓国メディア振興財団に委託せずに管理している場合が多いことを参考にしてください。 あるいは、ごく稀にCCLが適用されたメディア(ex.ウィキツリー)がある場合もありますので、利用目的によってこれを確認することが重要です。
たまにKDX(韓国データ取引所)が無料でニュースデータを公開することもありますが、この時、どこまでこのデータを活用できるのかという疑問が生じることがあります。
[ケース5]の場合
Q. 0円で購入したデータは自由に利用できますか?
A. この場合は、データ販売会員が定めた利用規約によって異なります。

出典.KDX 韓国データ取引所
KDXは基本的に下記のイ、ロ、ハの条項の共通利用範囲内でのみ使用可能であり、もし販売会員が追加条件をさらにかけた場合、共通利用範囲外の他の利用も不可能な場合がありますので、よく確認する必要があります。

出典.KDX 韓国データ取引所
ニュース記事のタイトル
一方、驚くべきことに、ニュース記事のタイトルは著作物としての価値が認められないため、著作権法の保護を受けられません。これは韓国著作権委員会が発行した「新聞と著作権」という冊子にも明記されています。

出典.新聞と著作権, 韓国著作権委員会, 2009
したがって、タイトルだけを見てニュース記事がどのカテゴリーに属するかを予測するモデルを作りたいときは、そのデータを合法的に活用することができます。
公正利用 (Fair-use)
以下の場合については、著作権者の許諾を得ることなく著作物を利用することができます。通常、教育を目的とする場合には、このような公正利用目的の範囲内であるため、著作物について大きくは問われません。
教育など
裁判手続きなどでの複製
政治的演説等の利用
学校教育目的などへの利用
時事報道のための利用
公表された著作物の利用
営利を目的としない公演・放送
史跡利用のための複製
図書館などでの複製
試験問題としての複製
視覚障害者などのための複製
放送事業者の一時的な録音・録画
美術・写真・建築著作物の展示または複製。
翻訳等による利用
時事的な記事及び論説の複製
プログラムコードの逆解析
正当な利用者による保存のためのプログラムの複製
-출처.韓国著作権委員会
著作権法のグレーゾーン、AI
多くの部分を著作権法で規定しているように見えますが、AIに関連する著作権法はまだ道のりが長いです。最近話題になっているChatGPTが生成したデータは著作物として認められるのでしょうか? これがもし可能だとしたら、私たちはChatGPTが生成したデータに対してどのようなライセンスを付けるべきか、どこまで利用できるのか、また、ニュース記事を基に新しい結果を出すAIモデルの著作権はどうなるのかなど、まだ私たちが解決しなければならない部分がたくさんあります。
したがって、明確な関連規範が整備されるまでは、まず著作物の著作権とライセンスの有無を確認し、利用可能な範囲を精査する必要があります。 今回のコンテンツではCCLライセンスについて主に説明しましたが、他の種類のライセンスも多いので、データを活用する前に必ず確認する必要があります。
AIを扱うすべての方が、合法的な境界内でのデータ作成方法を理解し、AIモデルをより良い方向に発展させ、また、現在の著作権法の限界についても関心を持つきっかけになれば幸いです。
-
-
2020年10月に設立したアップステージは、画像から目的の情報を抽出して利用できるOCR技術をはじめ、顧客情報と製品・サービスの特徴を考慮した推薦技術、意味ベースの検索を可能にする自然言語処理検索技術など、最新のAI技術を様々な業種にカスタマイズして簡単に適用できるノーコード・ロックコードソリューション「Upstage AI Pack」を発売し、顧客企業のAI革新を支援している。Upstage AI Packを利用すれば、データ加工、AIモデリング、指標管理を簡単に活用できるだけでなく、継続的なアップデートをサポートし、常時最新化されたAI技術を便利に使用することができる。また、AIビジネス経験を溶け込ませた実習中心の教育と堅実なAI基礎教育を通じて、AIビジネスに即座に投入できる差別化された専門人材を育成する教育コンテンツ事業にも積極的に取り組んでいる。
アップステージはGoogle、Apple、Amazon、NVIDIA、Meta、Naverなどのグローバルビッグテック出身のメンバーを中心に、NeurPSをはじめ、ICLR、CVPR、ECCV、WWW、CHI、WSDMなど世界的権威のあるAI学会に多数の優秀論文を発表し、オンラインAI競進大会Kaggleで国内企業の中で唯一2桁の金メダルを獲得するなど、独自のAI技術リーダーシップを確立している。アップステージのキム・ソンフン代表は、香港科学技術大学教授として在職しながら、ソフトウェア工学と機械学習を融合したバグ予測、ソースコード自動生成などの研究で最高の論文賞であるACM Sigsoft Distinguished Paper Awardを4回受賞し、International Conference on Software Maintenanceで10年間最も影響力のある論文賞を受賞した世界的なAIの教祖と言われ、合計700万ビュー以上を記録した「みんなのためのディープラーニング」講師としても広く知られている。また、アップステージの共同創業者には、Naver Visual AI / OCRをリードし、世界的な成果を出したイ・ヒョルソクCTOと世界最高の翻訳機パパゴのモデルチームをリードしたパク・ウンジョンCSOが参加している。