オープンソースLLMと韓国語モデルの生態系
2023/10/26 | 5分
-
ヘイリー (コンテンツコミュニケーション)
-
生成AIとオープンソースの動向が気になる方
韓国語LLMと生態系について知りたい方
-
最近、人工知能(AI)市場の 판도는様々なオープンソースの登場で変化しています。LLMの敷居を下げることで、生成型AI時代の新しい風として浮上した「オープンソースLLM」と、これがLLMエコシステムにもたらす波及力はどのようなものか見てみましょう。
-
✔️ オープンソースとは?
✔️ オープンソースLLMの登場
✔️ 主なオープンソースLLMモデル
✔️ オープンソースがLLMエコシステムに与える影響
✔️ 韓国語AI競争力強化のための'Open Ko-LLMリーダーボード'
最近、人工知能(AI)市場の 판도는様々なオープンソースの登場で変化しています。メタがLLaMaを誰でもアクセスできるオープンソースとして開放して以来、オープンAIやGoogleのようなビッグテックを除いた後発企業はモデルをオープンソースで出す傾向になりました。 今回のインサイトブログでは、LLMの敷居を下げることで生成型AI時代の新しい風として浮上した「オープンソースLLM」とは何か、また、これがLLMエコシステムにもたらす波及力はどのようなものなのかについて解説します。
オープンソースとは?
オープンソースソフトウェア(SW)は、人工知能、ビッグデータ、クラウド、IoTなど、第4次産業革命の核心技術とされる多くの部分で活用されています。オープンソースの登場背景を理解するためには、コンピュータソフトウェアの初期の歴史を見る必要があります。コンピュータが初めて開発されたとき、ソフトウェアは主に学界や研究機関で開発され、そのコードは自由に共有されました。 しかし、徐々に商業的なソフトウェア市場が成長するにつれ、多くの企業が自分たちのコードを非公開にし始め、このような流れに反発して1980年代後半、リチャード・ストールマン(Richard Stallman)がソフトウェアの本来の生産流通方式である情報共有方式を復元しようと「自由ソフトウェア運動」を始めました。 その後、関連財団や協会が設立され、オープンソースという用語が初めて登場します。
オープンソースとは オープンソースとは?
: ソースコードが公開されており、誰でも自由にレビュー、修正、配布できるソフトウェアを指す用語である。各オープンソースのライセンスによって、ユーザーがそのソフトウェアをどのように使用したり、修正したり、配布することができるかが決まる。
オープンソースは、特に言語モデルの開発需要が爆発的に増加する中、コスト削減の理由からLLM市場で大きな注目を集めています。 大量のデータ学習や独自のシステム開発をしなくても、オープンソースをファインチューニング(微調整)すれば、新しいモデルを迅速に開発できるからです。
オープンソースのメリット オープンソースのメリット
迅速で柔軟な開発環境:複数の人が同じプロジェクトに貢献しながら、アイデアを交換し、問題を解決できる環境を提供します。
拡張性:ユーザーのニーズに応じてコードを修正したり、拡張してプロジェクトの目的に合わせてカスタマイズすることができます。
コスト削減:独自のシステム開発をしなくても、無料で使用できるオープンソースソフトウェアを活用すれば、コストと時間を削減することができます。
オープンソースLLMの登場
新しいキーワードとして急浮上しているオープンソースLLMは、今年2月、メタがLLaMaを学界でアクセスできるようにして以来、これを活用した「sLLM」(small Large Language Model;小型言語モデル)が多数登場し、注目され始めました。 sLLMは通常パラメータが60億(6B)~100億(10B)個で従来のLLMに比べてはるかに小さいにもかかわらず、性能は劣らないため、低コスト・高効率の強みを持ちます。オープンAIの「GPT-3」はパラメータが1750億個、Googleの「LaMDA」(ラムダ)が1370億個、「PaLM」(パーム)が5400億個に達するのと比較すると、効率をより体感することができます。
マーク・ザッカーバーグメタプラットフォーム最高経営責任者(CEO)は昨年7月、LLaMa 2をオープンソースとして発表し、「生態系が開放されればされるほど、より多くの進歩が可能になると信じている」と言及しました。 このようにオープンソースを公開する企業は、AI技術に対する敷居を下げて、多くの組織と開発者が自由に競争し、革新を作り出すことができる生態系を造成することが、業界が発展する方向であるという観点を持っています。
主なオープンソースLLMモデル
では、多く活用されている主なオープンソースLLMモデルにはどのようなものがあるのでしょうか?
LLaMA

人間のフィードバックによる強化学習(RLHF)と報酬モデリングを通じて双方向会話に最適化したLLaMA 2-Chat
(出典: Llama 2: Open Foundation and Fine-Tuned Chat Models)
代表的なものとして、オープンソースLLMの普及をリードしたメタの「LLaMA」があります。商業的活用まで可能なバージョンであるLLaMA 2は2023年7月18日にリリースされましたが、強化学習(RLHF)と報酬モデリングを活用してテキスト生成、要約、質問と回答など、より有用で安全な成果物を生成することができます。LLaMA 2は7B、13B、70Bの3つのサイズに分かれています。モデルに使用されたパラメータ(parameter)の大きさによってモデル別の生成完了時間に差がある場合がありますが、以前のモデルに比べて精度の向上と有害なテキスト生成を防止する側面が強化され、AzureやWindowsなどの複数のプラットフォームでもファインチューニングが可能に拡張され、様々なプロジェクトに活用されています。
2. MPT-7B

出典:MosaicMLブログ
MPT-7B(Mosaic Pretrained Transformers)はMosaicMLが発表したオープンソースのLLMで1兆個のトークンで学習されたトランスフォーマーです。商業的にも利用可能で、基本モデルに加えて、これをベースに構築できる3つの派生モデル(MPT-7B-Instruct、MPT-7B-Chat、MPT-7B-StoryWriter-65k+)があります。MPT-7Bはメタの70億個のパラメータ数を持つモデルであるLLaMA-7Bと同等の品質を持つと言われています。
3. アルパカ

出典:スタンフォード大学
Alpacaはスタンフォード大学が公開した学術研究目的のオープンソースモデルです。スタンフォードの学生たちは、ChatGPT、Claude、Bing Chatなど様々なモデルが登場する中、依然として誤った情報や有害なテキストが生成される可能性があることを指摘しました。このような問題を解決し、技術的に進歩するためには学界の参加が重要であると考え、モデルの研究を続けるためにAlpacaを発表しました 。Alpacaは、MetaのLLaMA-7Bをベースに、言語モデルがユーザーの指示に適切に答えられるようにするInstruction-followingデータを活用してファインチューニングされました。
4.ビクナ

出典:LMSYS.org
LMSYS Orgが作成したVicunaもLLaMAをベースに作られています。ShareGPT.comで収集した7万件のユーザー共有会話で構成された学習セットをファインチューニングに活用したといいます。 Vicunaチームによると、GPT-4を審査員として使用した予備評価で、Vicuna-13BはChatGPTとGoogle Bardの品質の90%以上を達成したことが示され、オンラインデモと一緒に提供するコードは非商業目的であれば誰でも使用できます。
5. ファルコン

出典:技術革新研究所
Falconはアラブ首長国連邦(UAE)の技術革新研究所(Technology Innovation Institute)が公開したモデルで、Falcon 40Bは研究者と商用ユーザーの両方が活用できる代表的なオープンソースモデルの一つです。180Bモデルは1800億個のパラメータを使用し、3兆5000億個のトークンで学習し、優れた性能を持っています。
オープンソースがLLMエコシステムに与える影響
これまで見てきたように、オープンソースはAI技術へのアクセス性と透明性を高めることができるという純機能により、様々な部分で活用されています。もちろん、誤用に対する懸念のようなデメリットも存在しますが、それでもLLMエコシステムの発展にポジティブな影響を与えるという点、そしてビッグテックに比べて比較的資本が大きくない組織も効率的に研究し、新しいモデルやサービスを開発することができるという点が、オープンソースAIを持続させる要因なのです。
このような流れを受けて、自然言語処理分野の最大のオープンソースプラットフォームである「Hugging Face」も注目され始めました。ハギングフェイスは、世界中の様々な企業や研究機関が開発した生成AIモデルの性能を評価し、競争することができる「オープンLLMリーダーボード」を運営しています。 ここでは、500以上のオープンソース生成AIモデルが推論、常識能力、言語理解総合能力、幻覚現象(ハルシネーション)防止など4つの指標に対する評価に基づいて順位がつけられています。このリーダーボードは常時開放されており、モデルが新たに提出されるたびに評価を反映して更新されたリーダーボードを確認することができます。

出典:Hugging Face
特に国内企業の中では、8月にAIスタートアップのアップステージが開発した生成AIモデルがチャットGPTの基盤であるGPT-3.5の性能を超えて1位を獲得したことが知られ、話題を集めました。 アップステージは、7月にハギングペースを通じて30B(300億)のパラメータモデルを公開し、平均67点を獲得し、同日発表されたメタのLLaMA 2 70Bモデルを追い越し、国内LLM初の1位達成という快挙を成し遂げたことがあります。さらに、LLaMA 2 70B(700億)パラメータをベースにファインチューニングしたモデルを発表し、リーダーボード評価72.3点を記録し、グローバル1位を確定することになりました。
ハギングフェイスリーダーボード基準で生成AIモデルの代名詞とも言えるGPT-3.5のスコアを上回る事例はアップステージが初めてで、グローバル競争力を証明したアップステージのLLMモデル「SOLAR」(ソーラー)は、去る9月に生成AI活用プラットフォーム「Poe」のメインモデルに登用されました。 これはチャットGPT、グーグルファーム、メタラマ、エントロピッククロードに匹敵する性能を認められたもので、オープンソースを活用すれば、資本と人材が限られたスタートアップでもグローバルトップレベルのモデルを開発できることを証明した代表的な事例です。
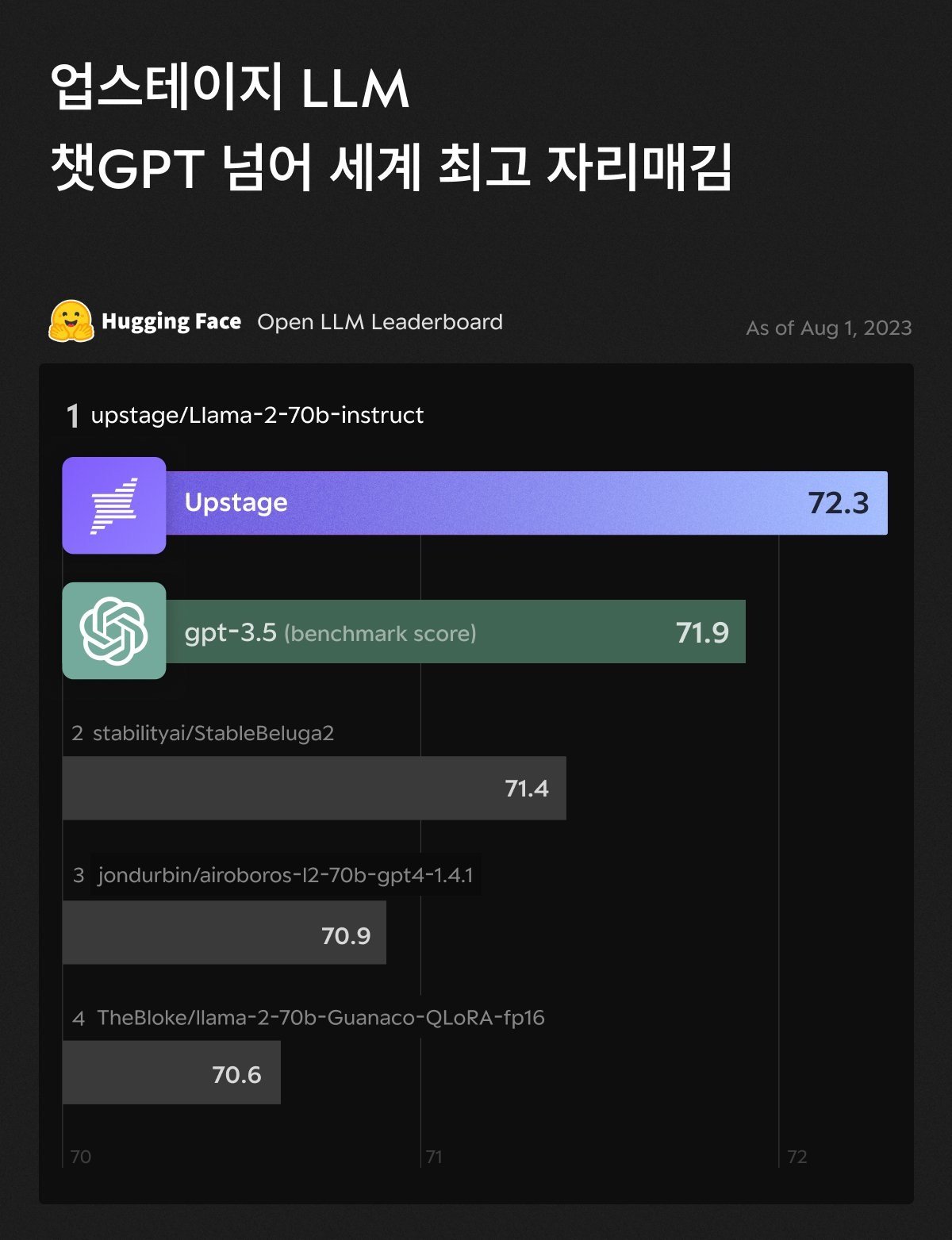
国内代表AIスタートアップUPSTAGEが開発した生成AIモデルがハググフェイスオープンLLMリーダーボード順位でチャットGPTを抜いて1位を獲得した様子 (23.08)
韓国語のAI競争力強化のための「Open Ko-LLMリーダーボード」。
国内でもオープンソースAI生態系拡大のための動きが活発化しています。ハググフェイスオープンLLMリーダーボードで1位を獲得したアップステージは、最近韓国知能情報社会振興院(NIA)と協力して韓国語LLMの性能を評価・比較することができる'Open Ko-LLMリーダーボード'を開設しました。 Open Ko-LLMリーダーボードは、ハギングフェイスが運営するオープンLLMリーダーボードの既存データを単に翻訳したのではなく、韓国の特性と文化を反映した高品質のデータを独自に構築し、韓国語特化型リーダーボードとしての強みを誇っています。 また、常識生成能力を評価する基準を追加し、多角的にモデルを評価できるようにしましたが、これを活用すれば、韓国で最も代表的なハラスメント例として知られている「世宗大王のマックブック投げ事件」などの事例も大幅に防止することができ、韓国語と歴史に適したモデルを比較・評価できるという点で意味があります。
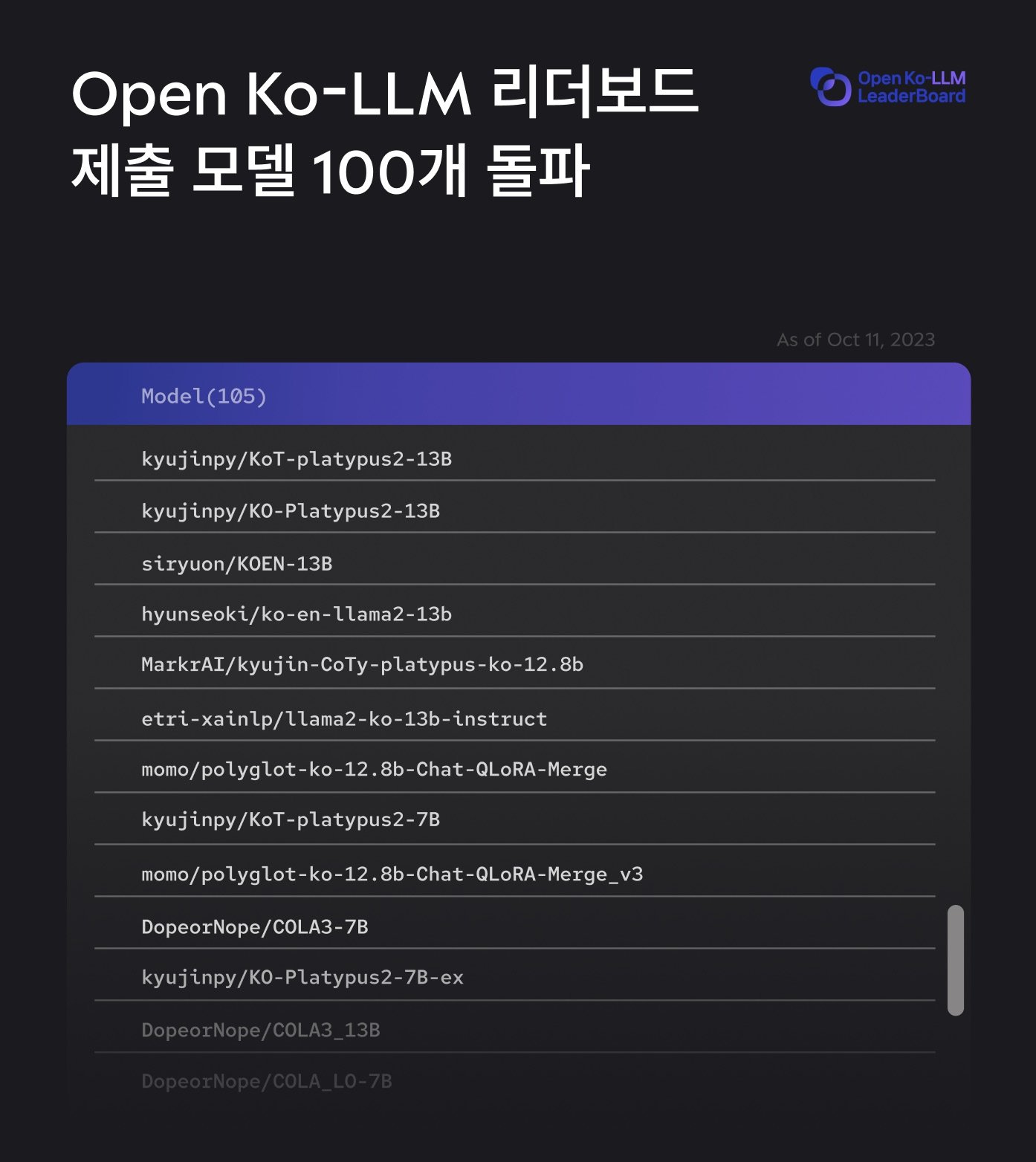
Open Ko-LLMリーダーボードは開設2週間で登録されたモデルが100個を超え、急激な拡大を見せています。 特に「Ko-Alpaca」、高麗大学の「KULLM(雲)」、「Polyglot-Ko」など、既存の有名な韓国語オープンソースモデルが総集結する様相で業界で韓国語特化LLM性能評価のバロメーターとして定着しています。これは、韓国LLMの独立のために1億語以上の韓国語データを貢献するパートナー企業に収益共有の共存モデルを提示する「1Tクラブ」とともに、韓国オープンソースLLM陣営の求心点として期待を集めています。
このように急速に進化している生成AI市場の中で、オープンソースはまたどのような波及と進歩を起こすのでしょうか。グローバル市場だけでなく、国内でもオープンソース陣営がもたらす革新を期待しています。
-
アップトークンクラブ Up 1 Trillion Token Club
-
アップステージは2020年10月に設立された韓国を代表するAIスタートアップだ。UpstageはHuggingfaceリーダーボードでオープンLLM史上初めてチャットGPTのベンチマークスコアを上回る性能で1位を獲得し、巨大言語モデル(LLM)業界で頭角を現している。このような技術力を基に、データセキュリティを最大化し、ハラスメントを解決した信頼できるプライベートLLMの標準を提示し、最先端の技術を企業が便利に使用できるように支援する。 また、アップステージのChat AI「AskUp」は140万人以上のユーザーを保有し、国内最大のAIサービスとして位置づけられている。もう一つのアップステージの代表ソリューションであるDocument AI Packは、世界最高権威のOCR大会を席巻したAI OCR技術を活用し、効率性と精度を高めて文書自動化を実現する。最小限のデータで事前学習されたモデルを通じて文書処理を最適化することで、手作業方式に比べてコストと時間を劇的に最小化する。最後に、教育プログラム「エデュステージ」を通じてAIビジネス経験を溶け込ませた実習中心の教育と確かなAI基礎教育を通じて、AIビジネスに即座に投入できる差別化された専門人材を育成する教育コンテンツ事業にも積極的に取り組んでいる。
アップステージはGoogle、Apple、Amazon、NVIDIA、Meta、Naverなどのグローバルビッグテック出身のメンバーを中心に、NeurPSをはじめ、ICLR、CVPR、ECCV、WWW、CHI、WSDM、DMLRなど世界的権威のあるAI学会に多数の優秀論文を発表し、オンラインAI競進大会Kaggle(Kaggle)で国内企業で唯一二桁の金メダルを獲得するなど、独歩的なAI技術リーダーシップを確立している。アップステージのキム・ソンフン代表は、香港科学技術大学教授として在職しながら、ソフトウェア工学と機械学習を融合したバグ予測、ソースコード自動生成などの研究で最高の論文賞であるACM Sigsoft Distinguished Paper Awardを4回受賞し、International Conference on Software Maintenanceで10年間最も影響力のある論文賞を受賞した世界的なAIの教祖と言われ、合計700万ビュー以上を記録した「みんなのためのディープラーニング」講師としても広く知られている。また、アップステージの共同創業者には、Naver Visual AI / OCRをリードし、世界的な成果を出したイ・ヒョルソクCTOと世界最高の翻訳機パパゴのモデルチームをリードしたパク・ウンジョンCSOが参加している。